


Scaling Uber to 1000 Services: Insights and Regrets
This post is based on a few things that you should be prepared for while moving toward microservices.
Matt Ranney, Chief System Architect at Uber, talked about the scale near 2015 that they had achieved, they were growing rapidly fast, before he joined Uber they had ~200 engineers, and in the next 1.5 years, it went to 2000. that’s a huge scale because they were expanding to other countries like China and India.
Interestingly, he points out the normal behavior we all possess: if you were to ask yourself to advise your younger self, your younger self is too naïve to take it and thinks they are in control. However, there are still a few things we all learn the hard way.

But why microservices?
Microservices allow teams to move and deploy quickly, without dependencies. Additionally, everyone is the owner and responsible for their service.
It is such a nice concept; you get to scale your part of the system, and the system scales well with each team focusing on their end.
Microservices come with complexity and expense. Everyone is aware of costs like how hard it is to debug in a distributed environment, but…
Let's talk about Less Obvious costs
Everything is a trade-off; you gain some, you lose some. There is always an opportunity cost. Whatever you do, it will have consequences. You just have to check if they matter to you.
Build around problems: Sometimes, people choose to build something new rather than fix an old one. Because who wants to read old code? It makes people sick. Engineers would rather choose to create new solutions, rather than fix current ones.
Talking to people: If you want to fix something, you must communicate with the teams responsible for maintaining it. But Engineers are like… Oh, so you’re saying I, the TechnoGod, should go and talk to people… with words???!!! Let me mentally prepare myself for that.
Keep your own biases: People love building things with their own biases. If there is scope for discussion then the team will decide something you might not be in favor of and to avoid that, Engineers build things with their biased framework and practice. And then defend why it's the best.
Now all of this might not lead in favor of org though, but still happens.
Some other costs
Too many languages: You have the flexibility to code in any of them, and a few quarters down (and maybe before that), you have N languages circulating. This leads to a hard time when reorganizing teams because people have achieved specialization, and if you want to unplug them and put them somewhere else, you have to give them time to learn, which maybe the organization can afford or maybe not.
Language bias is also an issue: Python users consider themselves superior to Node, and X is better than Y, and things like that. This breaks the organization into fragments, and people play Node vs Flask on the foosball table.
Operations
Since everything is disconnected, if Service A is blocked due to some issue/requirement unsatisfied, they have to wait. Either the other service stops their task and gives Service A priority, or they finish theirs first and then help Service A.
The other way around is for Service A people themselves to go and fix the problem. But what if they don’t know the framework Service B uses? What if their deployment is broken and needs some particular configuration to deploy, etc.?
Disconnecting is easy as it will help you grow, but you won’t be able to help others because you are… Disconnected.
Performance
- When everyone is using a different framework, measuring performance can become challenging because things vary from framework to framework.
Teams create dashboards as per their convenience, which can cause confusion among teams.
Uber decided to have at least a common set of metrics that will be configured for every service, so you can monitor the stats of other services you are related to even if you are not working on it. To maintain some scale of uniformity among variable environments.
- There is a certain culture that always says you don't have to optimize that much on design or code, optimize for dev velocity instead, they say getting a machine will solve the optimization problem rather than hiring an engineer.
This becomes hard to control with time, and one-day cloud bill will shoot up or any service will go down so, you need to have at least somewhat performant service.
Uber solved this problem by having minimal passing performance criteria for all services, that will be deployed. So you can have a safety net. Even if your service is not the most efficient but you have a track of stats that this service can handle. Pre-mature optimization is considered bad, but having some optimization is a must.
So maybe “good” is not required, but you at least “know” where you stand, which will eventually help.
Tracing
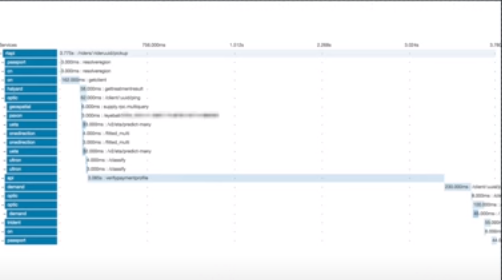
Here we have a simple tracing waterfall of the request cycle, it is easy to identify which part of the service request is causing the delay.
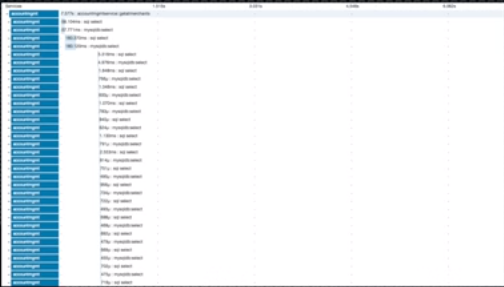
This is now a different scenario, the single request here is doing many DB tasks, yes all DB calls are fast but why are there so many, here DB team will report yes each request is being served fast, and as per them DB is fine up and running, but there are thousands of DB calls each request, that's a N+1 case to DB call.
Things like these go untraced but because tracing tools help you can analyze this kind of scenario. Of course, you should prioritize these, otherwise keeping on making microservices gives instant gratification but at this kind of cost.
Logging
People tend to dump a variety of things in different capacities and formats whenever they see an opportunity. This may lead to inconsistency due to a lack of standardization, especially since logging comes free. some individuals tend to overload the system by logging every minor detail. This makes it hard to analyze the logs with tools like Hadoop or Elastic Search.
Here you have noticed that the pattern is standardization, yes scale is achievable but many things need to be standardized to some extent and I guess this is how orgs achieve scalability.
they built ZAP for logging. https://medium.com/codex/level-based-logging-in-go-with-uber-zap-a8a90aa40672
Twitter faced a similar issue, you can learn about it in this video by Arpit Bhayani for that.
Migration
Everyone is always migrating something somewhere. As you grow you think you will migrate in non-peak time but again at the global level somewhere it is peak time in another part of the world, so be comfortable with migrations. Code level, data level, etc. for security and compliance reasons, just like there is always a release note of “bug fixes and performance improvements”.
Load Testing
Don’t get sad, once you are told oh you’ve built it and it took whole 3 sprints now we are going Load Testing, gonna push your service to peak and kill it with chaos monkey. This kind of scares people but this is how it operates in the real world, so accept the fact and be ready for these scenarios.
Emotion as a Service
Today you build something, any infra tool or anything to help your org, and initially it worked well, you and everyone were happy, but then 6 months later you find out Amazon released that as a new service at a low cost. This can make anyone sad now you have to defend your baby.
Be prepared for scenarios like that, there is always a high chance something better will come up, don't get sad. Pre-grief on it.
These are a few things that you should know or at least be aware of that will happen once your organization will scale, so you are prepared for and it doesn’t come as a surprise. Few problems are solved, and others are waiting for better solutions, maybe you can come up with one, there will always be good problems to solve.
This is the main talk that I referenced, I encourage you to watch it because this blog is just a glimpse of it. You will learn a lot.
I have recently started writing about my system design learnings and will be sharing them along the way.